How To Use Partitions In Hadoop. The major difference between partitioning vs bucketing lives in the way how they split the data. partitioning divides a table into sections based on the values of specific columns, such as date, city, and department. For example, in the above table, if we write the below sql, it need to scan all the records in the. Each table in the hive can have. The main goal of this hadoop tutorial is to provide you a detailed description of each component that is used in hadoop working. Let’s create a partition table and load data from the csv file. The data file i’m using to demonstrate partition has columns recordnumber, country, city, zipcode, and state columns. to create a partitioned table in hive, you can use the partitioned by clause along with the create table statement. in hive there are 2 types of partitions available: both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). partitioning is a way of dividing a table into related parts based on the values of particular columns like date, city, and department. It’s simple to run queries on slices of data when you use partition. To identify a certain partition, each table in the hive can have one or more partition keys. Static partitions & dynamic partitions. When user already have info about the value of partitions and.
from blog.cloudera.com
To identify a certain partition, each table in the hive can have one or more partition keys. Each table in the hive can have. in hive there are 2 types of partitions available: For example, in the above table, if we write the below sql, it need to scan all the records in the. The major difference between partitioning vs bucketing lives in the way how they split the data. to create a partitioned table in hive, you can use the partitioned by clause along with the create table statement. When user already have info about the value of partitions and. both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). Let’s create a partition table and load data from the csv file. It’s simple to run queries on slices of data when you use partition.
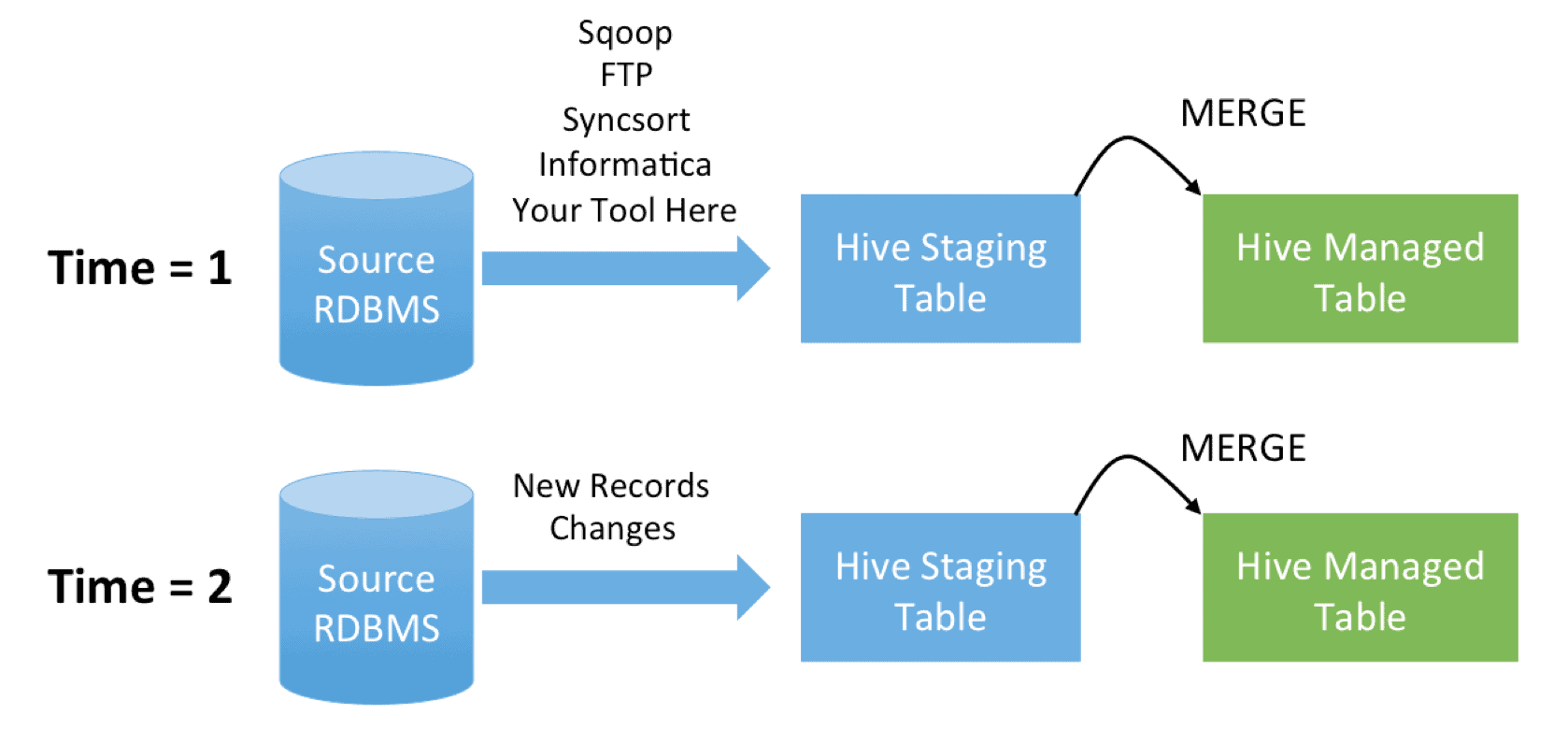
Update Hive Tables the Easy Way Cloudera Blog
How To Use Partitions In Hadoop in hive there are 2 types of partitions available: Each table in the hive can have. The major difference between partitioning vs bucketing lives in the way how they split the data. both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). To identify a certain partition, each table in the hive can have one or more partition keys. When user already have info about the value of partitions and. The data file i’m using to demonstrate partition has columns recordnumber, country, city, zipcode, and state columns. For example, in the above table, if we write the below sql, it need to scan all the records in the. Let’s create a partition table and load data from the csv file. in hive there are 2 types of partitions available: to create a partitioned table in hive, you can use the partitioned by clause along with the create table statement. The main goal of this hadoop tutorial is to provide you a detailed description of each component that is used in hadoop working. It’s simple to run queries on slices of data when you use partition. partitioning is used to obtain performance while querying the data. partitioning divides a table into sections based on the values of specific columns, such as date, city, and department. partitioning is a way of dividing a table into related parts based on the values of particular columns like date, city, and department.